ScholarFlow — 真实学习流程的自动化闭环
一个围绕真实学习流程持续运行的自动化系统。用户继续用 Obsidian 和 GitHub 做最少量记录,ScholarFlow 把课表、作业、调课、跑步、日报、周报、知识补全,以及可订阅的课表日历接成一条长期运转的学习闭环。
不是 Demo,而是我每天在用的系统
课表、作业、调课、跑步、日报、周报、知识补全都来自真实学习行为,不是为了展示而临时拼接的数据流。
不是单点脚本,而是一套可复用的 Agent 引擎
它不是“自动生成课表”这么简单,而是把记录、触发、执行、回写、复盘串成长期稳定的协作闭环。
先把学习场景做实,再谈迁移能力
它确实具备向其他场景迁移的结构基础,但当前真正被验证的是学习管理闭环,这让它的表达更可信。
先用一屏看懂这套系统的输入、执行和结果
这套系统最重要的不是某个单点功能,而是输入、执行和结果已经被接成一条稳定链路。
输入层
用户继续在 Obsidian 和现有记录流里输入最少量信息,不需要学习新的平台或后台。
执行层
GitHub Actions 负责调度,脚本与 Agent 负责解析、计算、生成和回写,把分散事务自动串起来。
产物层
最终结果回到课表、作业、日报、周报和研究笔记,不停留在日志或一次性对话里。
它已经接手了哪些真实学习工作
这不是“未来计划做什么”,而是当前系统已经持续处理、并能回写结果的事务范围。
课表与调课
从课程数据到日程视图、ICS 导出,再到调课变更后的同步更新,保证网页、Markdown 和 iPhone 订阅日历始终一致。
作业与倒计时
把作业信息转成可追踪的任务列表,自动计算紧急度和剩余时间。
跑步与进度
持续记录运动行为,生成热力图和阶段性统计,不让习惯追踪只停留在口头目标。
日报与周报
从多源记录里自动汇总当天和当周产物,减少临时回忆和重复整理。
知识分析
扫描已有产出物,识别已经学过的内容和仍然存在的知识空白。
自主研究
把发现空白、搜索资料、生成笔记和自评沉淀接成后续闭环,而不是停在提醒层。
不是只有流程,系统已经在持续产出结果
评估这类项目,关键不只是“能不能跑”,还要看它有没有稳定产物。课表、周报和日报就是最直接的证明。
每天自动回到“今天上什么课、这周怎么排”
课表页不仅给出当天是否有课,还会回写本周第几周、哪几天有课,以及每天的时间、课程和地点。这说明系统已经能把结构化课程数据稳定转成可直接使用的结果。
课表可以直接进入 iPhone 日历,而不是只停留在网页里
系统会自动导出 ICS,并通过 GitHub Pages 发布固定订阅地址。这样课表不只是“能看”,而是能进入手机系统日历,成为真正的高频入口。
不是一句总结,而是带统计的周度复盘
周报不仅记录时间范围,还汇总 Git 提交次数、涉及文件数、日记录天数、作业状态和跑步次数。这说明它已经能把多源活动聚合成结构化周度视图。
把一天发生的事情压缩成可读、可追踪的日记录
日报会把课程、待办、提交次数、文件变化和运动进度集中回写,既能快速浏览,也能保留长期积累价值。
真实学习闭环架构图
先看清楚这套系统怎么从“手动记录”走到“自动产出课表、日报、周报和研究笔记”。这里重点不是炫技,而是证明闭环已经成立。
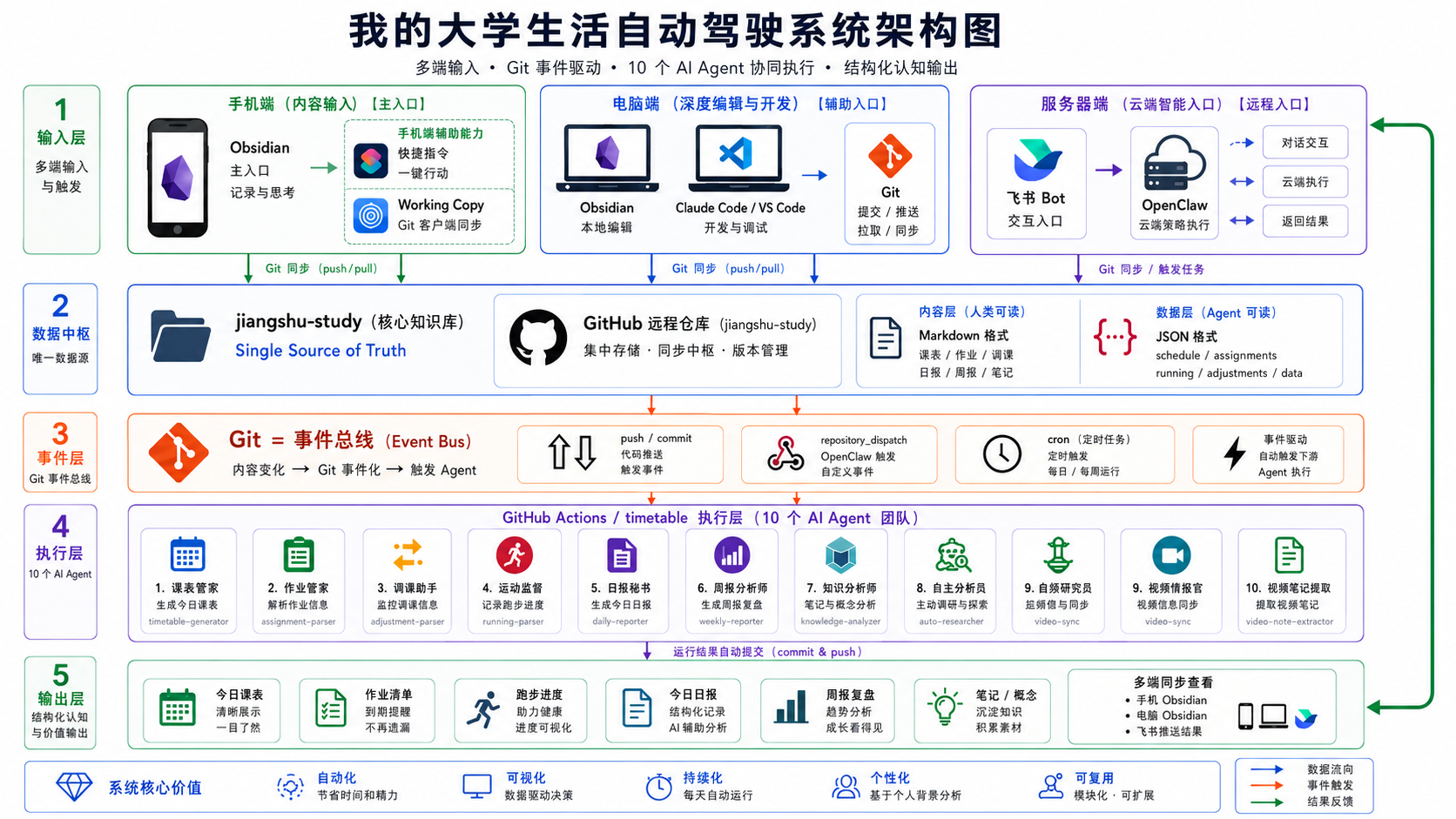
页面里优先保留完整总览,细节阅读通过弹窗放大完成,避免横向滚动破坏展示节奏。
先看输入入口,再看 Git 触发与 Agent 执行,最后看结果如何回到 Obsidian 与结构化产物里。
从手机端 Obsidian 与快捷指令开始,用户依旧使用熟悉工具,不需要额外学习新的操作系统。
Git 在这里承担事件总线角色,把提交、同步、调度与 Agent 执行流程稳定地串联起来。
系统最终输出不是停留在日志里,而是回到课表、作业、日报、周报与知识笔记等真实可读产物。
从日常记录到结构化产物,这条链路是怎么闭合的
不是让用户迁移到新平台,而是在现有记录方式之上,把分散任务接成一个长期运行的自动化系统。
记录
继续在手机 Obsidian 里做最少量输入。
触发
Git 提交与同步动作触发后续工作流。
执行
Agent 自动解析、计算、调度与生成。
回写
结果回到课表、作业、日报和知识笔记。
不是概念图,而是已经持续运行的系统
用少量、直接、可验证的信息回答“它真的跑起来了吗”。
从 2026 年 3 月上线后持续使用。
定时、推送与手动触发并存。
课表、作业、调课、运动、日报、周报、知识分析、自主研究。
执行层负责自动化,内容层保留可读产物与长期知识沉淀。
为什么它不是一个普通的自动化小工具
这里不直接喊“领先”或“创新”,而是把最关键的区分点摆出来,让访客自己判断它和普通作品的差异。
不只是一个 AI 聊天界面
单轮问答只能回答一次,ScholarFlow 会在没有人盯着的情况下继续执行:定时生成、事件触发、结果回写、长期复盘。
不只是几个脚本拼在一起
不是“脚本跑完就结束”,而是有状态、有产物、有上下游协作、有知识沉淀和人机分工边界。
不要求用户迁移到新平台
用户不需要迁移到一套陌生系统,只要继续使用现有的 Obsidian、GitHub、飞书,迁移成本极低。
结果直接进入系统级入口
很多自动化只把结果留在网页或聊天框里,ScholarFlow 已经把课表发布成可订阅日历,让自动化结果进入 iPhone 日历这个真实使用场景。
信息不该散落在各个系统里
这里不讲宏大愿景,只讲真实学习流程里最容易断掉、最值得自动化接管的部分。
- 课表、作业、调课和运动记录分散在不同位置,维护成本高,也很容易遗漏
- 很多任务不是难,而是高频且琐碎,时间一长就会断掉,最后既没有提醒也没有沉淀
- 日报、周报和复盘往往依赖临时回忆,真实过程没有被结构化保存下来
- 已经学过什么、还缺什么、下一步该补什么,缺少持续更新的知识诊断机制
- 记录和自动化常常是两套东西:要么内容可读但无法计算,要么脚本能跑但结果留不下来
- 手机日历是日常使用最频繁的入口之一,但很多学习系统无法把课表稳定同步成可订阅日历
- 用 Obsidian 作为统一输入入口,保留熟悉的记录体验,不要求迁移到新平台
- 用 GitHub Actions 和脚本负责解析、计算、调度与回写,把高频流程变成自动执行链路
- 把课表、作业、调课、跑步、日报、周报接成一个持续运转的学习闭环,而不是彼此孤立的小工具
- 通过知识分析与自主研究流程,补上“记录之后如何发现空白并继续学习”的后半段
- 把最终结果回写成 Markdown 和 JSON,保证既能自动处理,也能长期阅读、复盘与追踪
- 在内容仓库发布固定 `ICS` 地址,让 iPhone 和 macOS 直接通过“已订阅的日历”消费自动化结果
系统为什么能长期稳定运转
总览图看全貌,这里只补最关键的三层结构与运行关系。
交互层
手机端统一输入入口,用户在熟悉工具里做最少量记录,先把记录成本压到最低。
执行层
GitHub Actions 承担调度中枢,Agent 脚本负责解析、计算、生成与回写。
数据层
JSON 存结构化状态,Markdown 存可读产物,让自动化结果真正留下来。
为什么这套系统值得继续深入看
它的价值不在“会不会聊”,而在于它已经稳定接手了真实学习中的高频事务,并把这些事务变成了可持续积累的结果。
真实运行而不是概念展示
这不是为了展示临时拼出来的流程,而是已经和真实学习行为绑定在一起、持续产生课表、日报、周报和研究笔记的系统。
极低输入门槛
用户在最熟悉的工具里写几行字即可。不要求学新系统、不要求装新App。Agent负责剩下所有解析、计算、提醒、回写工作。
双仓库边界清晰
内容仓库负责阅读与沉淀,执行仓库负责脚本、状态和自动化流程。内容与逻辑分离,让系统更容易维护,也更容易扩展。
零成本持续运行
GitHub Actions 免费额度驱动,无服务器、无数据库、无专门运维。它不是一页 PPT,而是已经连续运行并持续产生真实结果的系统。
结果不仅可读,还可订阅
课表现在不只回写 Markdown,也会自动导出为 ICS 并通过 GitHub Pages 发布订阅地址,真正进入手机日历这个高频入口。
支撑这套系统落地的关键技术
技术栈在这里主要承担“可实现性证明”,不再与主视觉区争抢注意力。
完整设计说明
上面先看整体结构和真实证据,这里再展开完整的系统说明、Agent 分工与运行边界。
展开完整设计说明包含核心理念、问题定义、系统架构、Agent 团队与可扩展性说明。
↓
包含核心理念、问题定义、系统架构、Agent 团队与可扩展性说明。
ScholarFlow 不是一个“看起来像 AI”的界面,而是一套已经在真实学习流程里持续运行的自动化系统。它把课表、作业、调课、跑步、日报、周报、知识补全,以及可订阅的课表日历这些高频事务,从分散记录变成稳定闭环。
这个项目在解决什么
大学学习里最容易失控的,往往不是某一件大事,而是大量重复、小碎、但又持续重要的事务:课表会变、作业会堆、运动记录会断、日报周报容易拖、学过什么和没学会什么也很难持续追踪。
很多工具只解决其中一个点,但 ScholarFlow 的目标不是再做一个单点工具,而是把这些环节接起来:
- 用户继续用熟悉的 Obsidian 做最少量记录
- GitHub Actions 和脚本负责触发、解析、计算、生成与回写
- 最终结果回到 Markdown、JSON 和可订阅的 ICS 日历,形成可读、可复盘、可追踪的长期产物
当前已经接管的真实事务
- 课表生成:根据结构化课程数据生成 Markdown 课表与周视图
- 课表订阅:自动导出
ICS,通过 GitHub Pages 发布固定订阅地址,支持 iPhone / macOS 日历接入 - 作业追踪:解析作业信息、计算倒计时、按紧急度排序
- 调课处理:识别变更并同步更新下游数据
- 运动记录:沉淀跑步数据并生成进度统计
- 日报周报:聚合多源信息,自动输出结构化总结
- 知识补全:识别知识空白,触发搜索、生成、自评与沉淀流程
这些能力不是并排摆放的功能点,而是一条真实运行中的链路:记录 → 触发 → 执行 → 回写 → 发布 → 复盘。
为什么这套结构能长期运行
三层结构
- 输入层:保留 Obsidian 等熟悉工具,不要求迁移到新平台
- 执行层:GitHub Actions 负责调度,脚本与 Agent 负责解析、计算、生成和回写
- 产物层:JSON 保存结构化状态,Markdown 保存可读结果,ICS 负责对外日历订阅,既方便自动化,也便于长期阅读与接入
双仓库分层
- jiangshu-study:内容层,负责阅读、记录、沉淀和发布真实学习产物
- timetable:执行层,负责脚本、工作流、状态数据和自动化逻辑
这样的分层能把“内容”和“执行”彻底拆开:内容仓库更适合长期阅读与知识积累,执行仓库更适合维护脚本、工作流和状态更新,边界清晰,也更利于后续演进。
Agent 协作方式
- Git 在这里承担事件总线角色
- 定时任务、提交事件和手动触发共同驱动流程运行
- 单个 Agent 的失败不会阻塞整个系统的其他部分
- Git 历史天然保留了执行痕迹和内容演化过程
已经被验证的结果
- 10 个 Agent 持续运行
- 10 条工作流协同运转
- 2026 年 3 月上线后已稳定运行 2 个月+
- 已覆盖课表、课表订阅、作业、调课、运动、日报、周报、知识分析、自主研究等 9 类学习场景
- 零服务器、零数据库,依托 GitHub Actions 免费额度完成日常运行
这意味着 ScholarFlow 的价值不在“展示了多少概念”,而在于它已经稳定接管了真实学习中的高频事务,并把这些事务持续沉淀成可用结果。
当前边界与后续空间
我现在重点验证的是学习场景本身,而不是急着把它包装成一个什么都能做的平台。也正因为边界收得住,这套系统的表达才更可信。
如果未来要扩展,真正可复用的是这套结构能力:
- 低门槛输入
- 事件驱动调度
- 多 Agent 协作
- 可读结果回写
- 可订阅结果发布
- 长期知识沉淀
学习场景是第一块被做实的落地案例,但它更重要的意义,是证明这套闭环已经成立。
直接看真实运行现场,而不是只看宣传文案
执行仓库里能看到工作流、脚本和状态管理;内容仓库里能看到真实学习产物和长期沉淀。把这两个仓库一起看,才能理解它为什么不是空壳展示。